Part 1 - Summary
In part 1 of the An Illustrative Case Study of a Mildly Complex Problem, we introduced problem decomposition as an effective strategy for tackling multi-layered challenges frequently encountered in clinical informatics. The case I used as an example involved the inefficient distribution of work schedules to physicians via email in Excel format, which led to significant operational inefficiencies. We dissected the problem into manageable parts, starting with the automation of downloading Excel sheets from emails using Google APIs. In that post, I highlighted the importance of breaking down complex problems to understand and address them effectively, paving the way for a more in-depth exploration of the solution in subsequent parts.
Introduction of Part 2
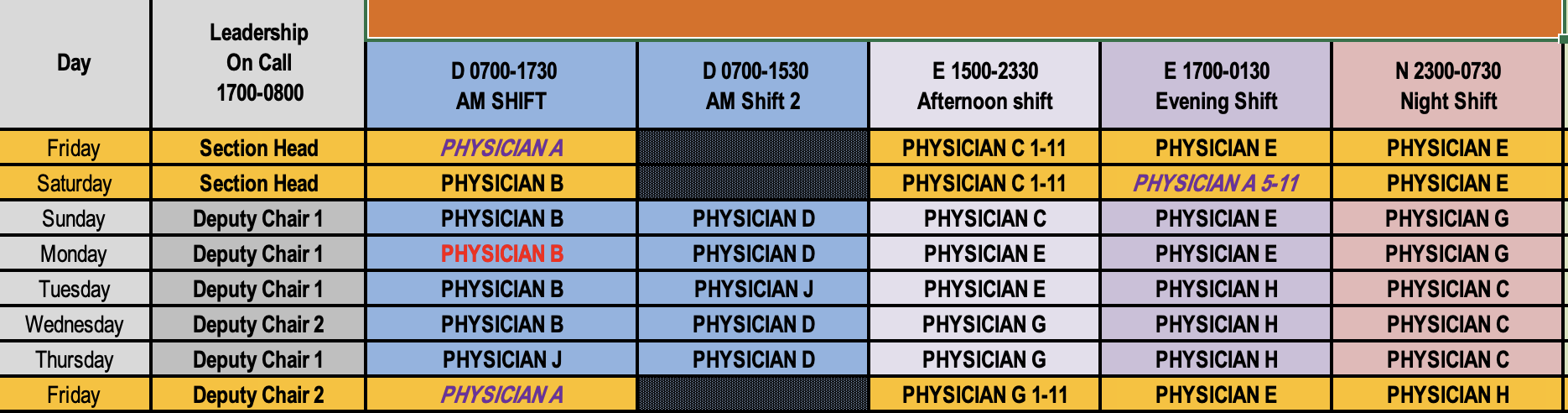
After successfully automating the download of the Excel sheets containing the physicians' schedules, we face the challenge of processing this data. The sheets are easy to read and understand for humans, however, this proves to be a much more difficult task for computers. In order to guide the computer to do this, we need to give it clear step-by-step instructions. The first step requires us the identification of the rows that contain essential header information—from now on, I will call these "anchor rows." These rows are critical for understanding the schedule's layout, as they delineate the beginning of relevant data segments, including shift names, start and end times, and other pertinent details. However, the complexity arises from the variability of these Excel sheets. In some instances, particularly during Ramadan months or other months with substantial changes, the Excel sheet may feature several anchor rows. To efficiently extract and utilize the schedule data, we must first identify all anchor rows accurately.
Identifying the pertinent month
In any given we are likleuy to receive shedule for the current month and the next month. Fir example on Oct 24th, we can get a revision in the October schedule, or a November schedule. Even the November schedule maybe preliminary or final or revision. Therefore, one of the first steps in the process is to determine the month of the schedule. This is important as we will see that in order to allow revision the data is saved in pickle files. Identifdying the months allows us to determine while file will be overridden and will have the information to modify the online calendars.
Defining bounds of the sheet
The process of finding anchor rows involves scanning the Excel sheets systematically to detect these headers. This is achieved by directing the computer to look for something that will only appear in an anchor row. For instance, it looks for specific keywords or patterns in cell organization that signify the start of a new header section. By identifying these anchor rows, we can segment the Excel sheet into manageable parts, each corresponding to a distinct scheduling period or section. In our example, based on experience from month after month schedule, I ended up using the keyword "Date" to identify an anchor row. (see figure 1.)
Once the anchor row(s) have been identified, we know where the data segments begin, but to fully automate the schedule extraction and to make sure the program doesn't run endlessly, we also need to define where these segments end. This involves determining the last row and column that contain relevant data. The variability of the Excel sheet layouts, especially with changes in scheduling or during specific months like Ramadan, means this cannot be a fixed position and must be dynamically identified for each sheet.
The process to find the last column and row is somewhat akin to mapping the extent of our data landscape. It requires directing the computer to scan horizontally (for the last column) and vertically (for the last row) from a known starting point(s). For me, the starting point was the first anchor row. However, determining the end was a little bit more tricky. In my case, I asked the computer to check 10 cells to the right of a cell in the first anchor. If there were 10 empty cells, then the computer defined that as the last column. Using a similar mechanism, the last row was also identified.
The Search
After we have meticulously identified anchor rows and established the data's bounds within the Excel sheet, our next endeavor involves what I will call "The Search." This step is dedicated to locating and compiling the work schedules for each physician by name, a task that is a series of nested loops. To achieve this, we deploy a methodical approach; it starts with a loop through a predefined list of physician names. For each name on the list, the program scans each cell within the search grid we defined above. When a match is found, the corresponding (row, column) tuple, marking the exact location of the physician's name within the grid, is added to a personalized list of tuples for that specific physician.
The accumulation of these tuples for each physician serves as the foundation for the next step: interpreting these coordinates to extract relevant scheduling information. By looping through each physician's list of tuples, we extract data associated with that cell, such as the shift code, which is instrumental in identifying the nature of the shift, alongside its start and end times. This extraction is not merely about collecting data points; it's about translating the raw information into a structured format that mirrors the operational logic of the clinical setting. This translation process is crucial, as it transforms free text data into actionable insights, enabling the automated system to generate a comprehensive and accurate schedule for each physician. Through this detailed and systematic search, we ensure that each physician's schedule is not only identified but also contextualized. This lays the groundwork for the final step of automating the distribution of these schedules, thereby enhancing operational efficiency and accuracy in a domain where precision is paramount.
Processing - from Raw text to structured fromat.
Once the search is complete, we have a list of tuples for each physician, each containing the coordinates of their name in the Excel sheet. As highlighted in the example above, sometimes a modifier can be inserted in the cell that provides contextual information. For instance, consider the Afternoon shift on Saturday in the aforementioned figure. The afternoon shift would normally run from 3 PM to 11:30 PM; however, the modifier in the cell overrides the normal hours. This adjustment was made using a step-by-step approach. The first thing I did was to look for a hyphen in the cell containing the physician's name. This hyphen indicates that there might be information overriding the data from the anchor row (e.g., "1-11" for a shift from 1 PM to 11 PM). If a hyphen is not found, then the cell in the same column as the physician's name, but located in the anchor row, is examined. The process also accounts for different formats expressing the same time range (e.g., "1p-11p", "1300-2330", "1PM - 11 PM", etc.). Each of these cases was specifically programmed to ensure comprehensive search coverage.
Furthermore, the code handles various scenarios, such as shifts that extend past midnight, adjusting the end date to the next day accordingly. It also refers to the anchor row and adheres to specific naming conventions based on the shift's characteristics or other keywords found within the Excel sheet. Additionally, it manages errors or ambiguities in shift times by providing default values and incorporating error codes to signal issues. This approach ensures that each physician's schedule is accurately recorded, reflecting any special circumstances or adjustments, thereby facilitating clear and effective communication of shift schedules. It also makes sure that program doesn't crash because of any errors.
Summary
This article represents a critical phase in our journey to automate the distribution of work schedules to physicians, a key initiative for boosting operational efficiency in clinical settings. Through the detailed process of identifying anchor rows, defining the data bounds of Excel sheets, and executing a meticulous search for each physician's schedule, we've laid a solid foundation for accurately interpreting and organizing schedule data. This meticulous breakdown underscores the necessity of clear, step-by-step instructions for computers to navigate tasks that are intuitively simpler for humans, illustrating the transformative power of automation in enhancing operational workflows. The forthcoming installment will delve into the crucial steps of data extraction, interpretation, and the automated updating of individual physician calendars, further streamlining the process and underscoring the importance of precision and efficiency in healthcare operations.
Disclaimer
This post serves as a guide on how to break down and solve a problem, rather than focusing on coding or Python best practices. As an amateur programmer, my approach to coding and the overall design of the program might not align with professional standards. Seasoned professionals might find aspects of my methodology and coding practices amusing or unconventional. My primary aim is to share the thought process and problem-solving strategies that I found effective, hoping they might be useful to others facing similar challenges, regardless of their coding proficiency.